Concept of an Information Product
An Information Product is an approach to describe a subset of data, analytical and visualisation requirements in a way that the business stakeholders can agree what they will get and the team can understand and deliver it in small iterations.
I often articulate Information Products as being similar to apps on your smartphone. Something you click on to achieve a task or outcome, which has a certain style of visualisation or interaction, that is bound by a set of data and is designed to be used by a certain group of users or persona’s.
For example the app we use to check our emails is very different to the app we use to play a game. Yet they both can be described using a common language based on the target audience, different data requirements and the way they are presented to achieve different actions or outcomes.
So we can use the same common language to differentiate Information Products.
An Information Product can be used to describe something that delivers:
- Dashboards
- Reports
- Data feeds
- Data API’s
- Data Sharing
- Visualisations
- Analytical models
These are but a few examples of how you can can be classified or described what an Information Product delivers.
The definition of an Information Product should include all the things required to deliver value to the customer, this includes:
- Code
- Tables/Views
- Data Models
- API’s
- Visualisations
An Information Product is a self contained, end to end product, it is not just the “last mile”.
The key is not what type of Information Product you are describing, but the refining of requirements so they are small enough for the team to commit to delivering that value to a business stakeholder. Ideally the defined Information Product is focussed enough to be delivered in one or two iterations.
One of the AgileData patterns I have seen experienced teams having success with is to describe an Information Product early by leveraging either the AgileData Information Product Canvas or Brief templates. This templates has been developed in an iterative manner with multiple different teams to create a way of lightly documenting each Information product without expending a large amount of wasted effort.
Information Product Canvas and Brief
They are designed to provide a common and shared language which enables the Information Product boundaries to be shared, understood and agreed with:
- stakeholders / customers
- delivery team members
- consumers of the information
When we first started iterating on the Information Product pattern we used a word document to define the boundaries. But as they say a picture is worth a thousand words so over time we iterated the process and adapted the Business Canvas pattern to create the Information Product Canvas.
Here is an example of the Information Product Canvas template.
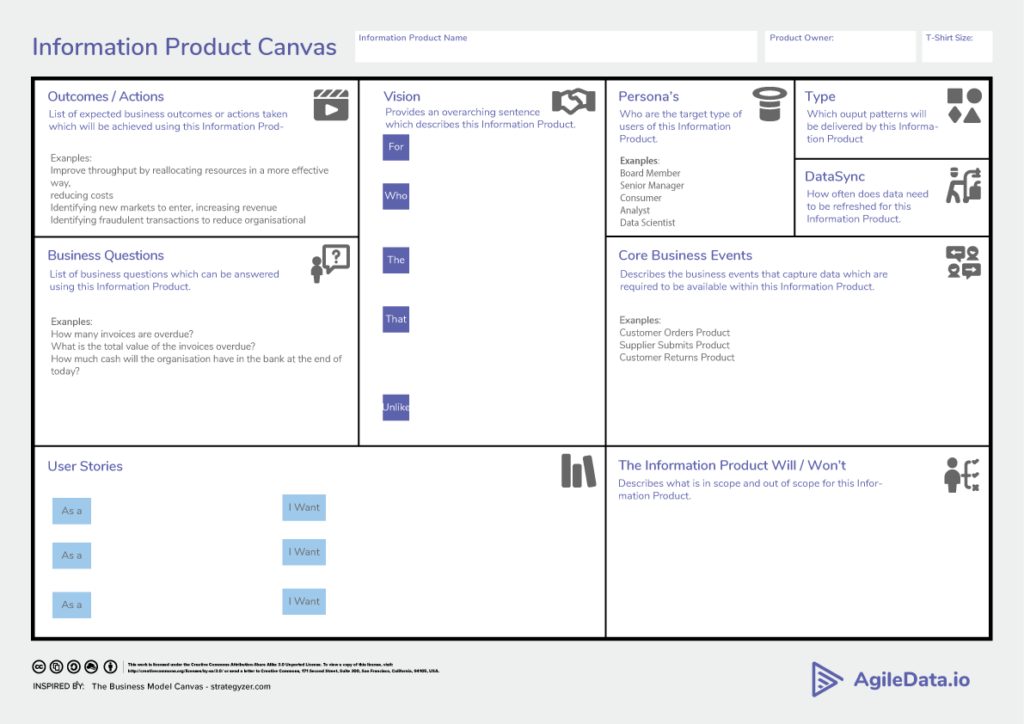
Here is an example of a completed Information Product Canvas.

You can download the Information Product Canvas Template in a variety of formats here.
The purpose of the Information Product Canvas is to give an Information Product a unique name and provide a way to understand and agree what is included and excluded. We need to understand who is the owner of the Information Product and is empowered to make trade-off decisions as it is developed. We need to understand the action that will be undertaken with the information and the outcome that will be achieved from that action. We need to understand the audience that the Information Product aims to serve, the business questions they expect to have answered with the information, the way they prefer the information to be delivered and when they expect the information to be current. We need to understand the core business events which produce the data we need to deliver the information. We need to understand the assumptions and trade-offs we are willing to make to deliver the information, what features will be delivered and what other things will and won’t be included. Lastly we need to include an elevator pitch which provides an understanding of the Information Products boundaries at a glance.
The Information Product Canvas and Brief templates are ways of lightly documenting:
- The Information Product name;
- The business outcome or benefit that will be achieved by using the Information Product;
- The action that will be taken as a result of the Information Product;
- The business questions that will be answered by using the information;
- The data-driven business processes that create the data required to deliver the Information Product;
- The audience (persona’s) that will use it;
- The visualisations or other ways it might be delivered;
- The features the users will require when accessing the Information Product;
- What will not be delivered in this Information Product.
Each of these are defined by leveraging other AgileData patterns such as Event Modeling, StoryBoards and Wireframing.
Information Product Canvas Areas
The areas can be grouped into 3 main themes:
- Reasons for the Information Product, what outcomes will be achieved if the Information Product is delivered;
- What needs to be delivered, what are the acceptance criteria for the Information Product;
- What do we need to know to deliver it, what additional details will help the delivery team to understand what is included and excluded in the Information Product and what data tasks do and do not need to be done to deliver it.
The areas can be filled out in any order and do not need to be filled out in one go. We often complete areas such as the Core Business Events after gathering the information in the other areas.
There is a typical flow we use when filling out the canvas so we will use that flow to explain each area. Feel free to experiment with your own flow to find a process that fits your preferred way of working.
Each of the Canvas areas have supporting AgileData patterns you can use to gather the required information. For the purposes of the next section we will focus on a brief overview of each area and link to the AgileData patterns so you can deep dive when required.
<<add links to AgileData patterns to each area>>>
01 – Give it a name and an owner

Information Product Name & Product Owner
In this area we capture the Information Product Name and the Product Owner for the Information Product.
Give the Information Product a name.
This will typically be used to identify the Information Product when talking with stakeholders or the AgileData teams about it.
Try to keep the name short but descriptive, when you have 100 Information Product Canvas in the backlogged well formed names will be very helpful. Some teams have used a numbering system in front, i.e 001, 002 etc, to help with identification.
Identify the Product Owner for the Information product.
This is a single individual who will engage with stakeholders and the AgileData team to make the required trade-off decisions as the Information Product is being developed.
Often we only add the actual Product Owner to the Canvas as we get close to the Information Product being prioritised within the next 3 to 6 month delivery horizon. Any of the Canvas details can be iterated and updated as required, so if a Product Owner is not identified at this stage use the name of the key stakeholder who is asking for the Information Product to be delivered.
02 – What questions will the Information Product answer

Business Questions
In the Business Questions area we gather the business questions the stakeholder hopes the Information Product will answer.
Business questions typically start with “how many”, “how much”, “how long”, “how often”. For example “how many customers do we have”, “how much did we earn last month” or “what was the total revenue last month”, “how long is it between an order being placed and the payment for that order” or “what is the average delay between an order and payment for the order”.
We are looking for the first three to five business questions that come straight to the front of the stakeholders mind. They might have more than five, that is ok let them carry on and add the Business Questions to the Canvas. At some stage the stakeholder will stop to think in more detail, at that stage we stop and move onto another area in the Canvas.
We are gathering these questions at this stage to get a general theme boundary for the Information Product and the Business Questions will help complete some of the adjacent areas. They are not the final set of questions that will be answered, they are not a locked set of requirements that the stakeholder will be unable to change. Let the stakeholder know that we can come back and add or iterate the Business Questions later, throughout the AgileData Way of Working process.
You will find that most stakeholders are able to complete this area very quickly. If they are unable to do that, this is a warning sign that they need to think about their requirements in more detail, or they are acting as a proxy agent for the real stakeholder.
We use these Business questions to help in both the Outcome/Action and Core Business Process areas. We also use them to validate the Persona area.
03 – What value will the Information Product deliver

Outcomes / Actions
In the Outcome/Action area we are looking to gather the business value that the Information Product will deliver. What Outcome will be achieved if this information is delivered?
We use this to help stakeholders prioritise the next most valuable Information Product which should be delivered next or to justify the cost/effort to deliver it.
Some stakeholders struggle to clearly articulate the value of the Information Product they are asking to be delivered. To assist them in this line of thinking we first ask them what Action they will take based on the Business Questions they have just mentioned. We are looking for a response to the question, “if you had this information at your finger tips, what action would you take with it?”
For example if we have a Business Question of “Who are the customers most likely to churn in the next month?”, we might get an Action of “Make a discount offer to customers likely to churn to reduce the number of lost accounts”.
A set of Action can then be used to elicit the Outcomes the stakeholder is expecting to achieve by investing in the Information Product.
For example we might get actions like “Make a discount offer to customers likely to churn to reduce the number of lost accounts” and “Identify potential customers who are less likely to churn and target them with a marketing campaign”. This would be under outcome of “Increasing the Life-Time-Value of our Customers to increase our profitability”
Ideally we would love to be able to quantify the actual dollar value of this outcome to help with the prioritisation and investment decision, but our goal is to elicit good requirements quickly, not boil the ocean. We can deal with the prioritisation challenge using other AgileData patterns.
We might find we have a data consumer not an information consumer as the stakeholder for these requirements. We will know this as the action is typically to use the data to find insights that are provided to somebody else, for example they will be taking the data produced and using another tool to create a dashboard or presentation for another set of consumers. That is ok, we have a choice, we can either create a short form of the Canvas that has the requirements to meet the data consumers needs, for example ignoring the Outcome/Action Area, or we can work with the data consumer to gather these requirements from the final information consumer.
04 – Who will use the Information Product
Persona’s
In the Persona area we are gathering who is going to consume the output of the Information Product, who is the final audience.
We reuse the Persona’s from the AgileData Persona pattern rather than a group of individual’s name. For example Information Consumer, External Consumer, Data Analyst. We may augment this information with the name of roles or the business units the Persona’s are located within if that level of detail has value. For example Finance, Human Resources or Executive Leaders.
The goal is to understand the audience who will consume the Information Product output. We tailor the delivery mechanism and the information output for the identified Persona.
For example if we are delivering an Information Product to a senior leader it will typically provide summary information, perhaps via a mobile app, compared to an operations user who may require detailed transactions, perhaps via a desktop browser.
Cross check the Persona’s identified with the Business Questions and Actions already identified, do they seem to correlate or is there a disconnect. For example, the identified Persona is an Executive Information Consumer, but the Business Questions are “what was the latest order placed and for how much” and the Action is “Contact customer to confirm order”.
The Persona may not be a group of individuals, for example it may also identify a system of capture that the data will be interfaced to, for example a Finance or Customer Relationship Management system.
The Persona area also informs the Type area
05 – How do they want to consume the Information

Type
In the Type area we identify the types of output the Information Product should produce.
It could be a Dashboard, Report, Data feed, Data API, Data Sharing, Visualisation, Analytical model or other output that is specific to your organisation. There could be one or multiple of these output types, for example both a Dashboard to be consumed by Information Consumers and a Dataset to be consumed by Data Analysts.
You could use the AgileData Wireframing pattern to flesh out a quick sketch of the output and attach it to the Information Product Canvas depending on your AgileData Way or Working.
Cross check the Types identified with the Business Questions and Persona’s already identified, do they seem to correlate or is there a disconnect. For example, the identified Persona is an Executive Information Consumer, but the Type is an API.
06 – When do they want the Information refreshed

DataSync
The DataSync area is where we determine how often the information should be refreshed, when new information should turn up in the Information App so it can be consumed.
If you ask the stakeholder when they want the information available they will often think about when they want to access it, not when new data needs to be added. They will say they need access to the Information all the time, they are thinking in terms of when it is available, what is often referred to as a Service Level Agreement (SLA).
At this stage we are more interested in how often we have to sync new data from the System of Capture to the end consumable information. This piece of requirements is important to help the AgileData delivery team to estimate the complexity and amount of effort required to update the information at this frequency. There is a difference in engineering updates once a day, compared to every 2 hours or every 5 minutes.
Cross check it with the persona and delivery type to see if they align. Watchout for the “near real time” requirement. If you are told there is a requirement for near real-time, then ask if they are ok that each time they look at the Information it will have changed from last time they looked at it. What happens if two information consumers look at it 5 minutes apart, will they end up arguing who’s information is correct?
07 – What data is required

Core Business Events
In the Core Business Event area we want to understand what data is required to deliver the Information Product.
We don’t want to deep dive into every field that is needed, we can gather that level of requirements as we get closer to the Information Product being prioritised into a delivery interaction.
But we do want to understand the core of the data we need, which System of Capture it needs to be collected from, have we already collected it, has it already been designed and change rules applied, and therefore it is ready to consume. This helps the team estimate the complexity and effort to deliver the Information Product and also plays a key role in trade-off discussions with the stakeholders. They may agree for the team to deliver a subset of the data early as they will get value from that data, compared to waiting for all the data to arrive.
To help gather the data requirements quickly we use the “who does what” pattern to understand the Core Business Concepts and Core Business Processes that are required and document these. We do not document the detailed data requirements (yet). We find the “Who does What”, Core Business Concepts and Core Business Process patterns provide a shared language between the business subject matter experts and the AgileData team and stops the deep diving into detail we do not need at this stage of the process.
08 – What special features do they need

User Stories
The User Stories is the first of two areas we use to highlight data and product features that are important. The other being the Will/Won’t area.
For the User Stories we use the agile user story format;
For a [persona or audience]
I want [want feature do they want]
So that [why do they want it, what are they going to do with the feature when they get it]
The user story format tends to fit feature requirements whereas the Will/Won’t area tends to suit in and out of scope statements.
If you are using an off the shelf last mile tool, for example a visualisation tool like Looker Studio and you know the features the stakeholders have asked for are available in that tool, then they don’t need to be added here. We are looking for a small number of key features we know we will have to create and which we know are high effort or high risk.
09 – What is in scope and what is out of scope

The Information product Will / Won’t
The Will / Won’t area is the second of the two areas we use to highlight data and product features that are important. The first is the User Stories Area.
The Will / Won’t area has a series of statements that start with Will or Won’t which describe the in and out of scope requirements. They tend to be focussed on data or architecture type requirements.
We don’t want to boil the ocean so we focus on a small number of requirements that are high effort or high risk.
We find it is more important to identify the Won’t rather than the Will’s. Most stakeholders expect that whatever they state as a requirement will automatically be delivered, so when we agree a trade-off decision that something will not be delivered in the first iteration then it is important we add it to the Information Product Canvas so it is visible.
10 – What is the elevator pitch

Vision
The Vision statement area is where we create a quick elevator pitch for the entire Information Product Canvas. Think of it as the pitch you do to a senior leader while riding together for 2 minutes in an elevator. Or in the modern remote world think of it as the 2 minute pitch you do over zoom to get funding to have the Information Product delivered.
The Vision statement uses a fixed format that uses the following construct:
For who – Who will be the primary user or the primary sponsor of this Information Product. We don’t use the Persona’s here, we want a specific person or a specific role identified.
Who needs – What do they need this Information Product to help them achieve, what value will they gain if it is delivered. We grab this from the Outcome/Action area.
The – Names are important, so we combine the Information Product name and its primary delivery mechanism to create this
That – What does this Information Product actually provide. We grab the key business questions from the Business Questions area, or the key features we will deliver from the User Stories & Will/Won’t areas
Unlike – What is the alternative of not having this Information Product available. Often we state the current problem the Information Product is trying to remediate, but the age old automating a manual process is always a good starter for 10.
We create the Vision statement after we have completed most of the Information Product Canvas. We have seen lots of teams start by completing the Vision statement first with the key stakeholders before filling out the rest of the canvas areas. Remember, you craft your own way of working that flows the way that is successful for your team and your organisation.
11 – How long will it take to deliver
T-Shirt Size
The T-Shirt Size area is where the AgileData team provides a guesstimate of how long this Information Product may take to deliver.
We use T-Shirt sizes (Small, Medium, Large etc) as a way of providing relative sizing for delivery across multiple Information Products.
The AgileData team will use a series of ratios to standardise/moderate the T-shirt sizes. They will compare multiple Information Products to use sizing ratios across the Information Products, for example a Medium sized Information Product is twice the effort compared to a Small Information Product. They will also use the number of iterations as a ratio for the Information Product size, for example a Small Information Product is likely to be delivered in a single iteration, compared to a Medium Information Product which is likely to be delivered in three iterations.
The AgileData team is the only group who can size the Information Product, they are the only people with the knowledge and experience to have a reasonable guess. Watch out for an anti-pattern where other people apply sizing to the Information Product and then try to hold the AgileData team to account to deliver the Information Product within the T-Shirt size.
The T-Shirt size assigned by the AgileData team is a guess. Not an estimate, not a promise and not a commitment. Over time the AgileData team will get better at guessing the level of effort to deliver an Information Product based on the information in the Canvas (a bit like how a fine wine gets better over time). But it is still a best guess, the only time we will have certainty on what level of time or effort it will take to deliver is one the team has delivered it.
When to create or iterate a Information Product canvas
There are five major stages where the Information Product documentation is updated.
- Gather, Size & Prioritise
- Estimation and commitment planning
- Build Design
- As Built
- When the Information Product is changed in the future
Gather, Size & Prioritise
The initial version of the Information Product canvas is created, with the minimal amount of detail required. This allows a high-level estimate of effort to build the Information Products to be t-shirt sized and the Information Products to be prioritised.
The gathering, sizing and prioritising enables the Information Product roadmap/backlog to be populated.
Estimation and commitment planning
The Information Product brief is updated with more detail to enable it to be sized using story points during the backlog refinement. The aim is to ensure it can be delivered within the timeframe that is expected.
Build Design
The Information Product brief is updated with enough detail to enable the team to start development. This is typically done at the beginning of the delivery iteration, in conjunction with the Vision, Business Event discovery and Wireframing workshops.
As Built
The Information Product brief is updated to become an as-built document to confirm what the team delivered. Ideally the documentation as flipped to follow a documentation as code pattern by this stage.
Ongoing Changes
The Information Product documentation is updated, using a documentation as code pattern every-time a change is made to it.
Information Products relationship to data and code
One of the questions about Information Products I get asked a lot, is what is the relationship between an Information Product and the data or the code it relies on?
DORO — Define Once, Reuse Often
When we start working in the data domain we should be aware that data is a thing which should follow the DORO principle, it should be defined once and reused often.
AgileData Data Architecture
For our AgileData product we leverage a specific data architecture pattern to enable this reuse.
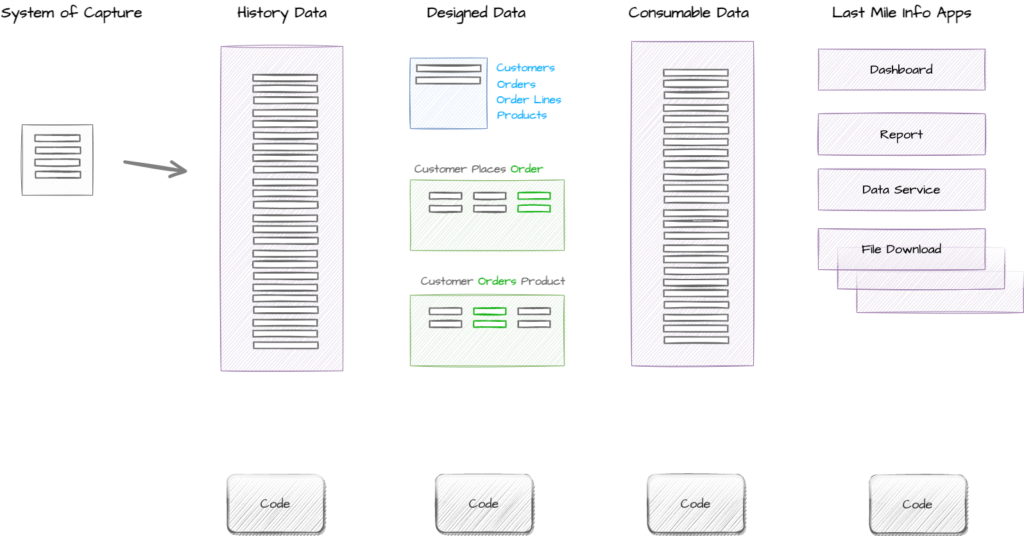
First we collect and store data from the system of capture so we have access to all historical data over all time. Second we model the data the first time we use it, to make it easier to use the next time, using our Core Business Event Modeling and Data Vault patterns. Third we create a consumable view of that data via automation, and last we use a last mile tool to deliver the data or information to the consumer in the format or interface that suits them best.
Each of these steps stores a physical or virtual view of data and this data or views are generated via some form of code.
You can adopt any data architecture which suits your organisations context. We are using the AgileData Product data architecture as a way of providing a concrete example of how data and code relates to Information Products.
So in the example above we have:
- Data being collected and stored from one system of capture;
- Core business concepts designed for Customers, Orders, Order Lines and Products;
- Core business processes designed for Customer Places Order and Customer Orders Product;
- Consumable data which makes all this designed data available for last mile use;
- Delivery of a Dashboard, Report, Data Service and File Extracts to a range of different consumers.
Iterative Delivery
One of the goals of the AgileData Way of Working is to deliver value to our stakeholders and customers as early as possible and to gather feedback as soon as possible so we can iterate the way we work based on this feedback.
So while we could do all the steps outlined above in a single iteration, there is value in breaking the delivery down into smaller iterations. We make defining these smaller iterations easier by using the Information Product pattern to create a clear boundary on what will and won’t be delivered in each iteration.
For the example above we would break the delivery down into three iterations.
First Iteration – Customer Dashboard
In this iteration the team are asked to create an Information Product that tracks some information about Customers. The preferred delivery mechanism is a Dashboard.
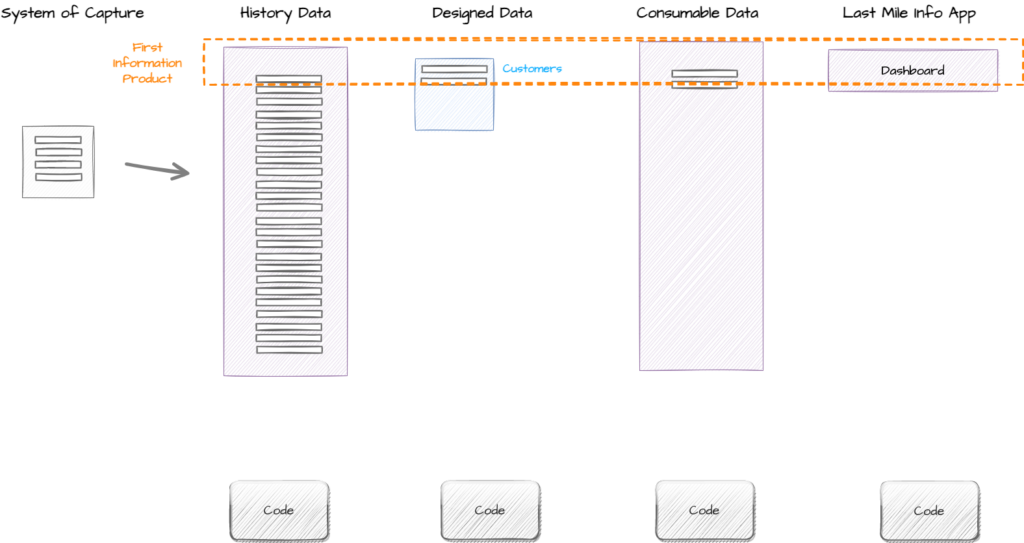
In this iteration we collect and store the data from the system of capture. We then model just the Customer concept, and this data becomes consumable via automation. Last thing we do is create a Dashboard that provides customer information to our Information Consumers.
Second Iteration – Customer Orders Report
In this iteration the team are asked to create an Information Product that provides a list of all Customer Order transactions. The preferred delivery mechanism is Report.
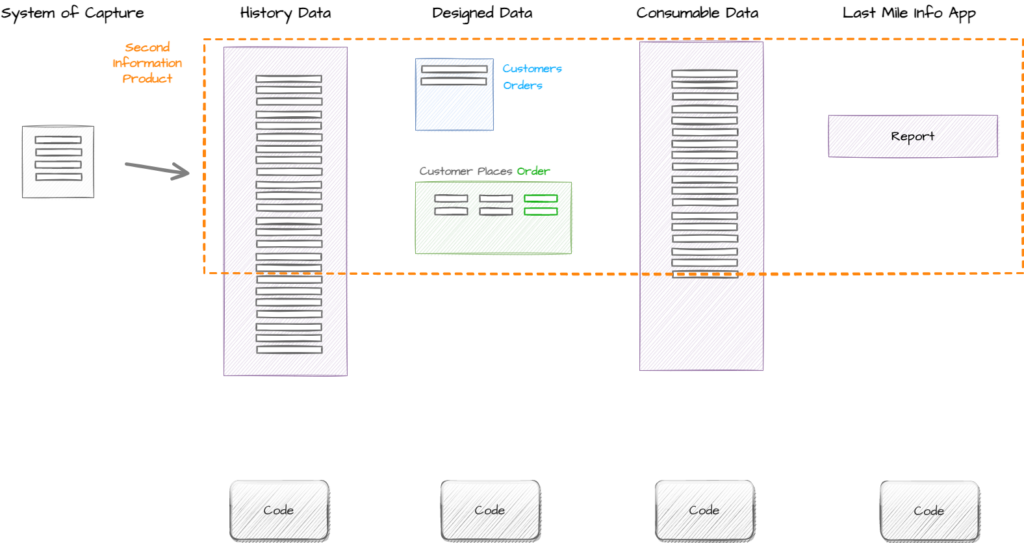
In this iteration we reuse the data we have already collected from the system of capture and we reuse the data we have designed for Customers.
We then add to this the data design for the Order concept and the Customer Places Order event. Again this data becomes consumable via automation and this time we use a last mile tool to provide a report of all Customer Orders to a different group of Information Consumers.
We could add information from Customer Orders Product into the Dashboard created in Iteration one, but the Information Product Owner doesn’t want us to spend time doing that effort as it has no value for their stakeholders so we don’t.
Third Iteration – Customer Product Orders Data Service
In this iteration the team are asked to create an Information Product to share the Products Customers have ordered with third party organisations. While the majority of the organisations that will consume this data have the ability to programmatically query a data service, a small subset do not and so will need files extracted and sent to them on a regular basis.
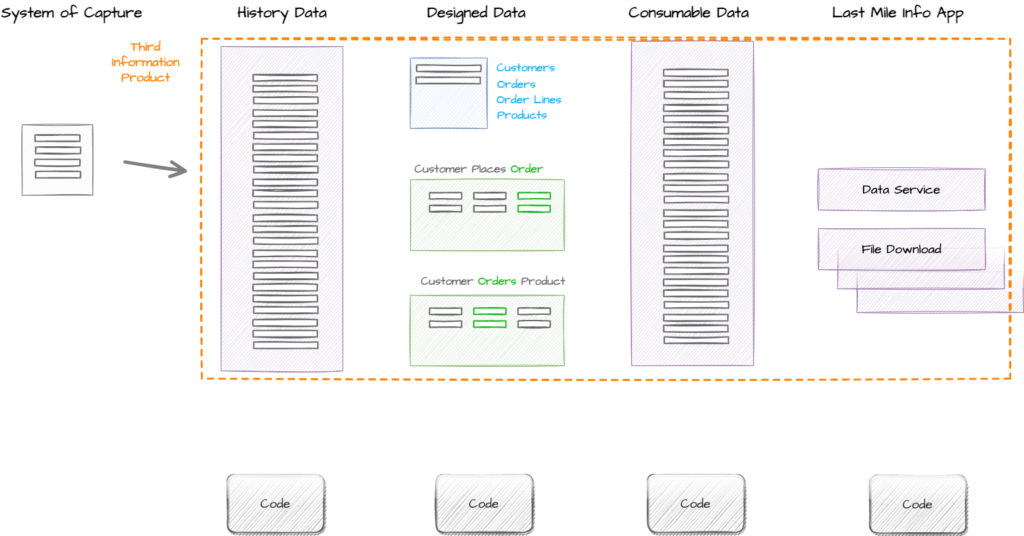
In this iteration we reuse the data we have already collected from the system of capture and we reuse the data we have designed for Customers and Orders.
We then add to this the data design for the Order Line and Product concept and the Customer Orders Product event. Again this data becomes consumable via automation and this time the team uses a last mile tool to provide an API which enables secure access to all Customer Product Orders by the external organisations. The team also creates a new platform feature which enables an internal consumer to manually download the data on a daily basis and upload it into the external organisations portal.
The team were keen to automate this capability, but the Information Product Owner has negotiated with the small group of external organisations that cannot programmatically use the API’s, that they have agreed to develop this capability in the next couple of months and so the extra effort to automate this process would outway its long term value.
The Chicken or the Egg
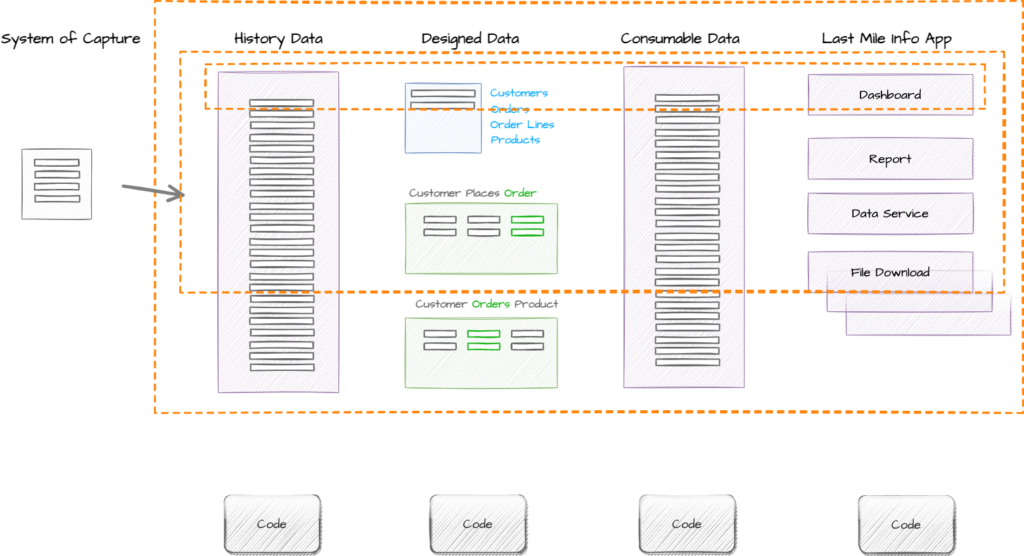
As you can see in this example we will find that over time we will end up with many Information Products accessing the same data and leveraging the same code.
We might find that a previous Information Product is updated by the delivery of a future Information Product, for example if the Information Product Owner had asked the team to update the Dashboard created in the first iteration to include order information.
What about data and code?
If many Information Products reuse the same designed data or consumable data what is the relationship between an Information Product, the data and the code that creates it?
There are five sets of code that an Information Product is dependent on:
- The code that automates the collection of data from the System of Capture (s);
- The code that designs the data;
- The code which makes the data consumable;
- The code that produces the final delivery output;
- The DataOps scaffolding code.
As you can see only the fourth set of code is unique to the delivery of the original Information Product, that is the code that produces the final delivery output, be it a dashboard or report, a data feed to another System of Capture or a data extract.
All the other sets of code have multiple Information Products dependent on it.
And even this pattern is not immutable, if the Customer Dashboard created in the first iteration was updated in the second iteration to include Order details we have to ask the question if the Customer Dashboard now relates to the original Customer Information Product or the later Customer Orders Information Product.
In the AgileData data architecture there is four layers of data that an Information Product is dependent on:
- The historical data stored as a result of collecting of data from the System of Capture (s);
- The data which has been designed as concepts, detail or events;
- The data which is consumable;
- The data stores in the last mile delivery (if that delivery mechanism stores data)
As you can see only the third set of data is consumed by an Information Product. But the consumable data is dependent on the historical and designed data, without it the consumable data cannot be updated or refreshed when new data is collected from the System of Capture.
Therefore all the data layers have multiple Information Products dependent on them.
The benefit of data reuse
As you can see, identifying the relationship between an Information Product and the data / code it relies on becomes difficult once we have delivered the second Information Product. So why would we reuse the data and the code, why wouldn’t we just create unique sets of data and code for each Information Product.
The reason is the effort to deliver additional Information Products should reduce overtime as new Information Products access data that has already been designed and is therefore already available. It provides the ability to deliver Information Products to our stakeholders and customers faster and with less effort compared to treating each one as a one off delivery.
This is the value we are unlocking by designing the data and not just creating a unique bunch of tables each time.
This is only true for Information Products that are based on the same core business events or data domains. When we start to work on Information Products which require data for a different core business event, then we will typically need to do some more design. When we start to work on Information Products that require data from another data domain, there is a high likelihood that we will need to collect data from a new system of capture.
The cost of data reuse
As a result of reusing the designed data, we end up with multiple Information Products being coupled to the same data. When the structure or content of this data changes there is a larger blast radius as multiple Information Products are impacted.
The good news is with multiple Information Products there is a larger group of users to tell you when the data has mutated, but seriously one of the goals of the AgileData Way of Working is we should identify when data has mutated before our customers do. Luckily there are a number of AgileData patterns that help us achieve this goal including automated data observability, data maps and self healing data mutation techniques which minimises the downside of data reuse.
The other downside is it is slightly harder to scale the AgileData squads/pods/teams if they are all working on Information Products that are using the same designed data, as there is a chance of one squad impacting another squad. Again we have some AgileData patterns such as the Information Product brief that helps with this problem.
Whats the alternative?
The alternative is you create a new set of data and code for every Information Product, which will solve some of the dependency issues. But it will result in minimal reuse so will never result in the benefits that reuse of data and code brings.
Also when data in a system of capture mutates, it will still impact every Information Product that is dependent on data from that system, regardless if you have reused the designed data or not.
Don’t sweat the small stuff
Just like it’s a waste of time to work out what came first the chicken of the egg, so it is trying to work out the boundary of an Information Product to data and code once the original Information Product has been delivered.
However there are a bunch of AgileData patterns that help to maintain a set of boundaries for an Information Product that are useful to reduce the complexity which arises with reuse.
Information Product Anti-Patterns
An anti-pattern is a common response to a problem that looks like a great idea but usually ends up making things worse.
An anti-pattern doesn’t mean it will also fail, but it does mean it is higher risk and so you should be cautious when using it. Some examples of Information Product Anti-Patterns are:
Information Products are just a reports.
While a Information Product often results in a report or dashboard, into todays modern agile data world, it can more often than not be a data service that provides data via an API, a set of resuable metrics, sharing of datasets or an analytical model that creates a score on demand.
One Information Product to rule them all.
One of the goals of the Information Product pattern is to define a set of boundaries which enable it to be delivered in a small number of iterations. If your Information Products are massive, then this will be difficult. So a Information Product of “Customer Life Time Value” should probably be decomposed into smaller Information Products, for example Customer Revenue, Customer Cost, Customer or Product Margin, Customer Propensity to Churn and finally Customer Life Time Value.
Information Product FAQ
No.
If you are using a time box pattern for your iterations, aka a Scrum centric approach, I have found that three week time-boxed iterations seem to work best for a team when they are starting out.
Ideally the Information Product will be defined in a way that it can be delivered within the three week iteration, but sometimes that is not practical. If that’s the case its ok to deliver the Information Product over multiple iterations, in that scenario I suggest you focus on the acceptance criteria that will be delivered in each iteration.
Overtime as the team matures their AgileData Way of working, they should focus on being able to decompose the Information products down to a set of requirements that can be delivered in a single iteration. The reason is we want to deliver value to the stakeholders as soon as possible and we want feedback as soon as possible.
Is an Information Product just another name for a report?
No.
While an Information Product is often used to describe a report, it can also be used to describe a data service or API, an analytical model or a complex dashboard.
Can’t I just use User Stories to define an Information Product instead?
Yes.
You can start with a large user story and refine it into a number of smaller user stories which can be planned, estimated and committed to by the team to be delivered in an iteration.
However in my experience without the additional details we capture in the Information Product document, the team often struggles to refine the large user story into small enough units of work.
As with all patterns within the AgileData Way of Working, it is the conversations we value over the document.
The Information Product pattern is designed to provide just enough details to improve the team’s conversations on how they will deliver value to the stakeholder / customer as early as possible. And to allow the Stakeholder / Customer to understand what they will have delivered and whatt they will not.
Is there a software solution I can use to capture these?
No, not that I am aware of anyway.
But if you end up creating one,or finding one, please send the details my way so I can update this content.
We are using a flow based agile way of working not iterative delivery, is there still value defining Information Products?
Yes.
One of the challenges for a data analytics team who are using a flow based way of working, is it is difficult for the team to define something as complete (Done Done). There is a tendency for the work to be iterated multiple times.
The boundaries that you identify when defining an Information Product helps the team to define when a task can be treated as complete.
Do we have to fill out the complete Information Product Canvas in one go?
No.
Capture as much of the information as you can when talking to the Stake who are requesting the Information Product, but you do not need to fill the Canvas out in one go.
We will often fill out just the Name and Product Owner and add the Information Product to the backlog, then fill in the rest of the details when the Information Product has been prioritised as up next in the 3 to 6 months time horizon.
However the person asking for the Information Product typically has a lot of details to mind when they ask for it, so we capture that in the Canvas as we talk to them, might as well capture it now if it is easy to capture.
We will often make some quick notes in the Core Business Process section if the data source is identified in the original conversation, but not identify the processes themselves until the Information product has been prioritised. Often we have already delivered another Information Product in the interim and can inherit the data from shared Core Business processes.
How long does it take to complete Information Product Canvas?
It typically takes an hour to discuss the requirements with the Stakeholder and complete the first draft of the Canvas.
If the Stakeholder has done the Canvas process before or has multiple related Information Products we have anaged to get the Canvas completed in 15 minutes.