One of the questions about Information Products I get asked a lot, is what is the relationship between an Information Product and the data or the code it relies on?
DORO — Define Once, Reuse Often
When we start working in the data domain we should be aware that data is a thing which should follow the DORO principle, it should be defined once and reused often.
AgileData Data Architecture
For our AgileData product we leverage a specific data architecture pattern to enable this reuse.
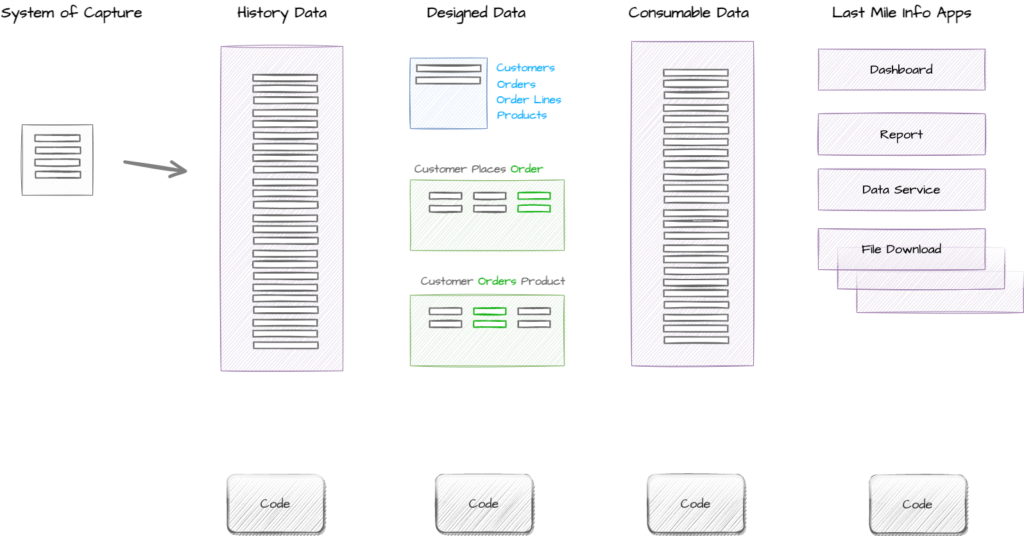
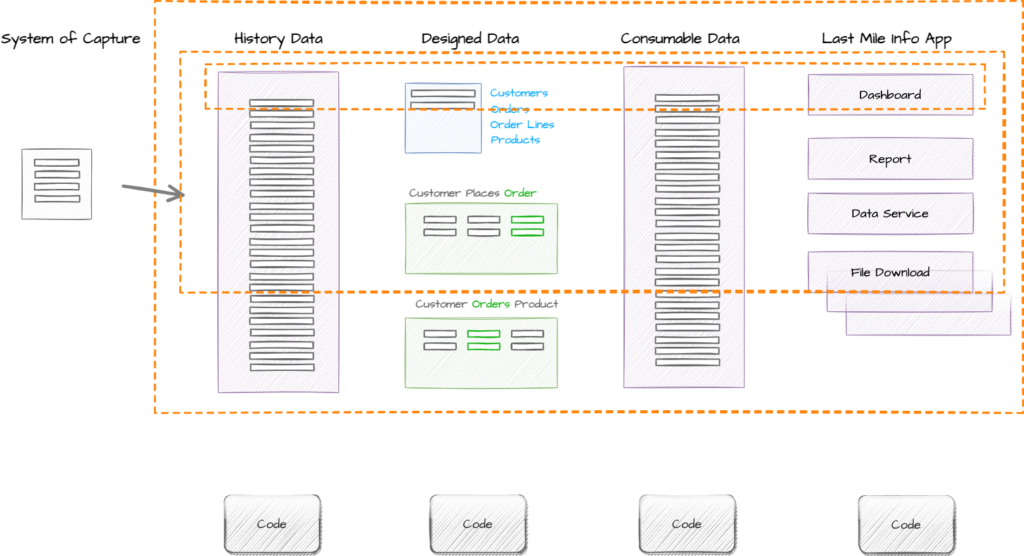
First we collect and store data from the system of capture so we have access to all historical data over all time. Second we model the data the first time we use it, to make it easier to use the next time, using our Core Business Event Modeling and Data Vault patterns. Third we create a consumable view of that data via automation, and last we use a last mile tool to deliver the data or information to the consumer in the format or interface that suits them best.
Each of these steps stores a physical or virtual view of data and this data or views are generated via some form of code.
You can adopt any data architecture which suits your organisations context. We are using the AgileData Product data architecture as a way of providing a concrete example of how data and code relates to Information Products.
So in the example above we have:
- Data being collected and stored from one system of capture;
- Core business concepts designed for Customers, Orders, Order Lines and Products;
- Core business processes designed for Customer Places Order and Customer Orders Product;
- Consumable data which makes all this designed data available for last mile use;
- Delivery of a Dashboard, Report, Data Service and File Extracts to a range of different consumers.
Iterative Delivery
One of the goals of the AgileData Way of Working is to deliver value to our stakeholders and customers as early as possible and to gather feedback as soon as possible so we can iterate the way we work based on this feedback.
So while we could do all the steps outlined above in a single iteration, there is value in breaking the delivery down into smaller iterations. We make defining these smaller iterations easier by using the Information Product pattern to create a clear boundary on what will and won’t be delivered in each iteration.
For the example above we would break the delivery down into three iterations.
First Iteration – Customer Dashboard
In this iteration the team are asked to create an Information Product that tracks some information about Customers. The preferred delivery mechanism is a Dashboard.
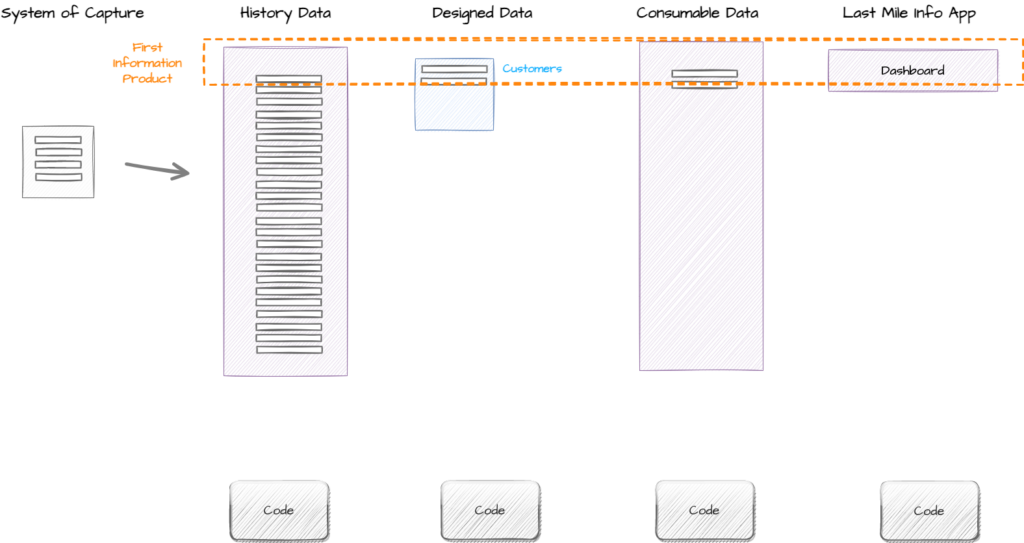
In this iteration we collect and store the data from the system of capture. We then model just the Customer concept, and this data becomes consumable via automation. Last thing we do is create a Dashboard that provides customer information to our Information Consumers.
Second Iteration – Customer Orders Report
In this iteration the team are asked to create an Information Product that provides a list of all Customer Order transactions. The preferred delivery mechanism is Report.
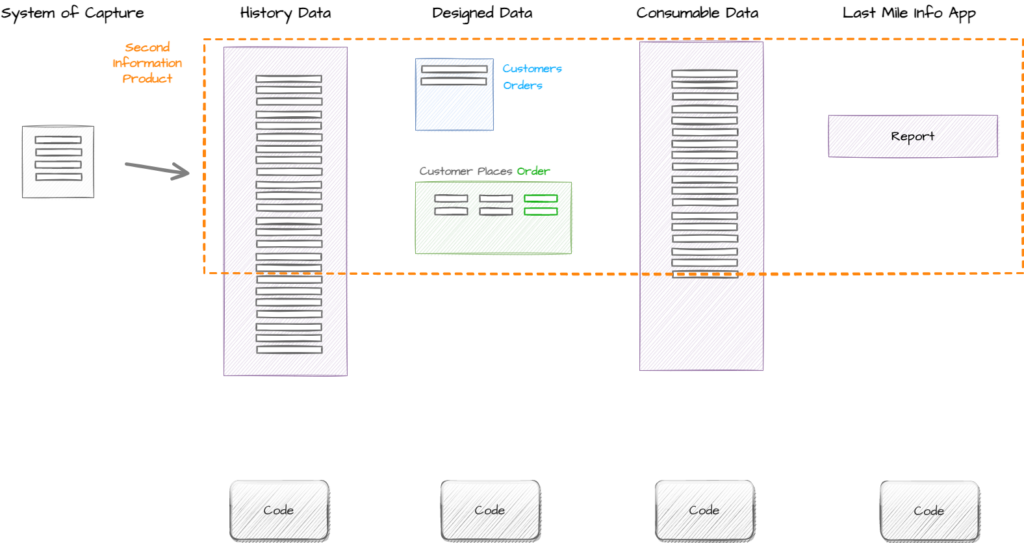
In this iteration we reuse the data we have already collected from the system of capture and we reuse the data we have designed for Customers.
We then add to this the data design for the Order concept and the Customer Places Order event. Again this data becomes consumable via automation and this time we use a last mile tool to provide a report of all Customer Orders to a different group of Information Consumers.
We could add information from Customer Orders Product into the Dashboard created in Iteration one, but the Information Product Owner doesn’t want us to spend time doing that effort as it has no value for their stakeholders so we don’t.
Third Iteration – Customer Product Orders Data Service
In this iteration the team are asked to create an Information Product to share the Products Customers have ordered with third party organisations. While the majority of the organisations that will consume this data have the ability to programmatically query a data service, a small subset do not and so will need files extracted and sent to them on a regular basis.
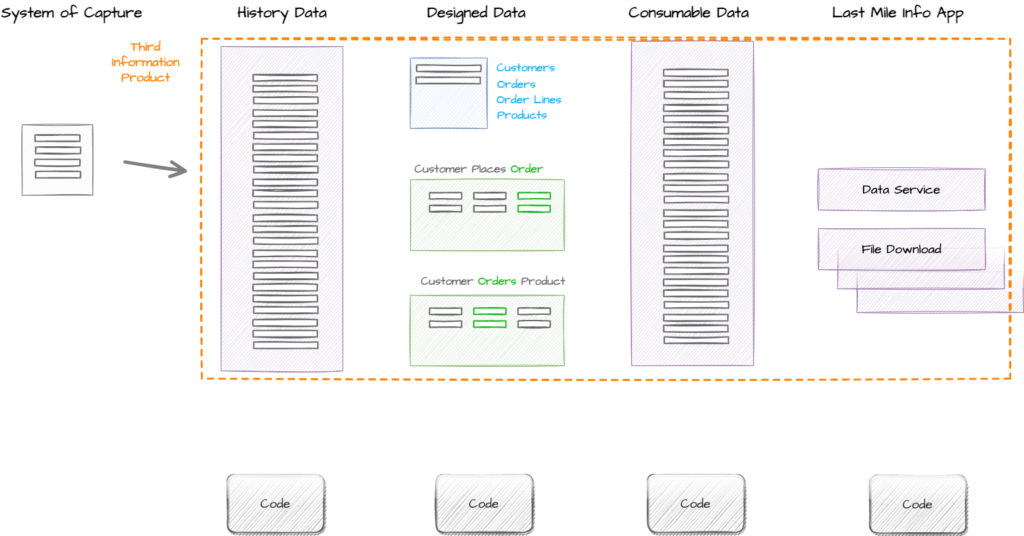
In this iteration we reuse the data we have already collected from the system of capture and we reuse the data we have designed for Customers and Orders.
We then add to this the data design for the Order Line and Product concept and the Customer Orders Product event. Again this data becomes consumable via automation and this time the team uses a last mile tool to provide an API which enables secure access to all Customer Product Orders by the external organisations. The team also creates a new platform feature which enables an internal consumer to manually download the data on a daily basis and upload it into the external organisations portal.
The team were keen to automate this capability, but the Information Product Owner has negotiated with the small group of external organisations that cannot programmatically use the API’s, that they have agreed to develop this capability in the next couple of months and so the extra effort to automate this process would outway its long term value.
The Chicken or the Egg
As you can see in this example we will find that over time we will end up with many Information Products accessing the same data and leveraging the same code.
We might find that a previous Information Product is updated by the delivery of a future Information Product, for example if the Information Product Owner had asked the team to update the Dashboard created in the first iteration to include order information.
What about data and code?
If many Information Products reuse the same designed data or consumable data what is the relationship between an Information Product, the data and the code that creates it?
There are five sets of code that an Information Product is dependent on:
- The code that automates the collection of data from the System of Capture (s);
- The code that designs the data;
- The code which makes the data consumable;
- The code that produces the final delivery output;
- The DataOps scaffolding code.
As you can see only the fourth set of code is unique to the delivery of the original Information Product, that is the code that produces the final delivery output, be it a dashboard or report, a data feed to another System of Capture or a data extract.
All the other sets of code have multiple Information Products dependent on it.
And even this pattern is not immutable, if the Customer Dashboard created in the first iteration was updated in the second iteration to include Order details we have to ask the question if the Customer Dashboard now relates to the original Customer Information Product or the later Customer Orders Information Product.
In the AgileData data architecture there is four layers of data that an Information Product is dependent on:
- The historical data stored as a result of collecting of data from the System of Capture (s);
- The data which has been designed as concepts, detail or events;
- The data which is consumable;
- The data stores in the last mile delivery (if that delivery mechanism stores data)
As you can see only the third set of data is consumed by an Information Product. But the consumable data is dependent on the historical and designed data, without it the consumable data cannot be updated or refreshed when new data is collected from the System of Capture.
Therefore all the data layers have multiple Information Products dependent on them.
The benefit of data reuse
As you can see, identifying the relationship between an Information Product and the data / code it relies on becomes difficult once we have delivered the second Information Product. So why would we reuse the data and the code, why wouldn’t we just create unique sets of data and code for each Information Product.
The reason is the effort to deliver additional Information Products should reduce overtime as new Information Products access data that has already been designed and is therefore already available. It provides the ability to deliver Information Products to our stakeholders and customers faster and with less effort compared to treating each one as a one off delivery.
This is the value we are unlocking by designing the data and not just creating a unique bunch of tables each time.
This is only true for Information Products that are based on the same core business events or data domains. When we start to work on Information Products which require data for a different core business event, then we will typically need to do some more design. When we start to work on Information Products that require data from another data domain, there is a high likelihood that we will need to collect data from a new system of capture.
The cost of data reuse
As a result of reusing the designed data, we end up with multiple Information Products being coupled to the same data. When the structure or content of this data changes there is a larger blast radius as multiple Information Products are impacted.
The good news is with multiple Information Products there is a larger group of users to tell you when the data has mutated, but seriously one of the goals of the AgileData Way of Working is we should identify when data has mutated before our customers do. Luckily there are a number of AgileData patterns that help us achieve this goal including automated data observability, data maps and self healing data mutation techniques which minimises the downside of data reuse.
The other downside is it is slightly harder to scale the AgileData squads/pods/teams if they are all working on Information Products that are using the same designed data, as there is a chance of one squad impacting another squad. Again we have some AgileData patterns such as the Information Product brief that helps with this problem.
Whats the alternative?
The alternative is you create a new set of data and code for every Information Product, which will solve some of the dependency issues. But it will result in minimal reuse so will never result in the benefits that reuse of data and code brings.
Also when data in a system of capture mutates, it will still impact every Information Product that is dependent on data from that system, regardless if you have reused the designed data or not.
Don’t sweat the small stuff
Just like it’s a waste of time to work out what came first the chicken of the egg, so it is trying to work out the boundary of an Information Product to data and code once the original Information Product has been delivered.
However there are a bunch of AgileData patterns that help to maintain a set of boundaries for an Information Product that are useful to reduce the complexity which arises with reuse.