There are a number of popular fixed mindset prioritisation patterns.
MoSCow
The Moscow prioritisation pattern is often used to prioritise tasks, features, or requirements in software development. The pattern consists of dividing tasks into four categories based on their level of importance and urgency: Must have, Should have, Could have, and Won’t have.
- Must have: This is the essential work that must be completed in order for the delivery to be considered a success. This work has a high priority and must be completed before moving on to other work.
- Should have: This work is important, but not essential. It should be completed if time and resources permit, but are not critical to the successful delviery of the desired outcome.
- Could have: This is work that would be nice to have, but are not essential or particularly important. They may be added if time and resources allow, but should not be given a high priority.
- Won’t have: This is work that is not necessary and may be postponed or omitted entirely if necessary.
Here’s an example of how it could be applied to a data analytics platform:
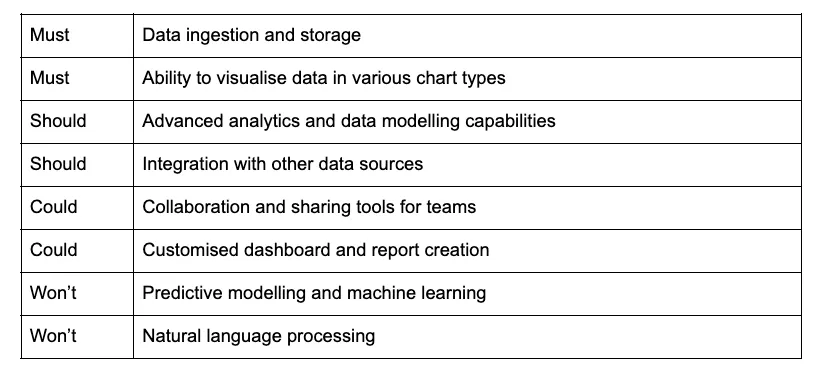
In this example, the Data Platform Product Owner has identified the essential features for the data analytics platform to function (Must Have), the valuable additions that would improve the product (Should Have), the desirable but not critical features (Could Have), and the ones that can be left out for now (Won’t Have).
Kano Model
The Kano model uses customer satisfaction patterns to prioritise customer requirements or product features. The model was developed by Noriaki Kano in the 1980s and is based on the idea that customer satisfaction with a product or service is influenced by a combination of performance, excitement, and basic needs.
The Kano model categories requirements into three groups:
- Must-haves: These are basic requirements that customers expect to be fulfilled. Failing to meet these requirements will result in customer dissatisfaction.
- Performance requirements: These are requirements that impact customer satisfaction directly proportional to the level of performance provided. The better the performance, the higher the customer satisfaction.
- Delighters: These are requirements that exceed customer expectations and provide a source of customer delight. Meeting these requirements can result in increased customer loyalty and positive word of mouth.
Here’s an example of how it could be applied to a data analytics platform:

In this example the Data Platform Product Owner has considered the impact of each feature on customer satisfaction, to help prioritise the development of features that are most important to customers.
Value-Effort
The value-effort prioritisation pattern is a method for prioritising work based on the value the work will deliver to stakeholders and the effort required to deliver the work. The goal of this pattern is to identify the work which will provide the most value for the least amount of effort, and prioritise that work first.
To use the value-effort prioritisation pattern, you would create a matrix with two dimensions: value and effort. The value dimension would measure the potential value of the outcome of the work for stakeholders, such as customers, users, or the organisation. The effort dimension would measure the resources required to complete the work, such as time, money, and effort.
Once the matrix is created, you would place each piece of work into one of four categories: high value/low effort, high value/high effort, low value/low effort, and low value/high effort. The work in the high value/low effort category is the work that should be prioritised first, as it provides the most value for the least amount of effort. The work in the low value/high effort category should be avoided or deferred, as it provides little value for a significant amount of effort.
Here’s an example of how it could be applied to a data analytics platform:
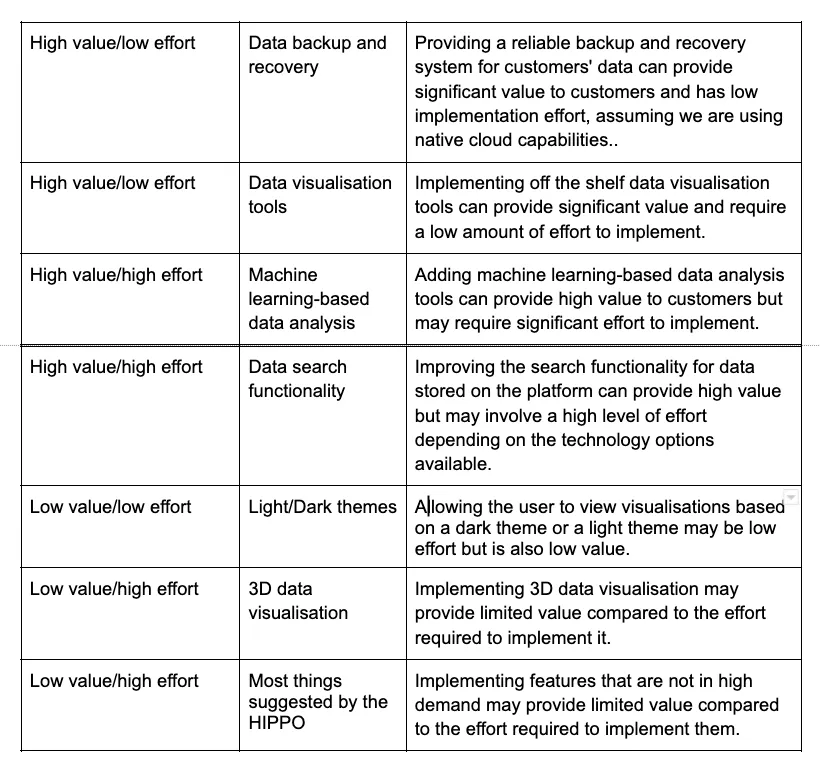
By considering both the value and effort of each piece of work, the value-effort prioritisation pattern can help the Data Platform Product Owner prioritise the teams efforts on the work that will provide the most value for the least amount of effort, and avoid wasting resources on work that will provide little return.
RICE
The RICE (Reach, Impact, Confidence, and Effort) prioritisation pattern is a method for prioritising work based on four factors: reach, impact, confidence, and effort. The goal of this pattern is to help teams make informed decisions about which work to tackle first, based on the potential impact it will have and the resources required to complete it.
- Reach: This refers to the number of people or systems that will be affected by the task. The higher the reach, the more important the task may be.
- Impact: This refers to the potential positive or negative impact that the task will have on stakeholders, such as customers, users, or the organisation. The higher the impact, the more important the task may be.
- Confidence: This refers to the level of confidence the team has in their ability to complete the task successfully. The higher the confidence, the more likely the task is to be prioritised.
- Effort: This refers to the amount of time, money, and manpower required to complete the task. The lower the effort, the more likely the task is to be prioritised.
To use the RICE prioritisation pattern, the team would assign a score to each piece of work for each of the four factors and then combine the scores to create a prioritisation score. The work with the highest prioritisation scores would be prioritised first.
Here’s an example of how it could be applied to a data analytics platform:
Implement a new data security measure
- Reach: High (affects all customers)
- Impact: High (protects sensitive customer data)
- Confidence: High (team has experience in implementing similar measures)
- Effort: High (significant time and resources required)
Prioritisation Score: (High Reach + High Impact + High Confidence + High Effort) = 12
Improve the data visualisation tools
- Reach: Medium (affects some customers)
- Impact: High (increases the usefulness of the platform)
- Confidence: Medium (team has limited experience with similar improvements)
- Effort: Low (relatively straightforward to implement)
Prioritisation Score: (Medium Reach + High Impact + Medium Confidence + Low Effort) = 9
Add a new data export feature
- Reach: Low (affects a small number of customers)
- Impact: Medium (useful for a specific group of customers)
- Confidence: High (team has experience in implementing similar features)
- Effort: Medium (modest amount of resources required
Prioritisation Score: (Low Reach + Medium Impact + High Confidence + Medium Effort) = 7
Based on these scores, the Data Platform Product Owner might prioritise the following tasks:
- Implement a new data security measure
- Improve the data visualisation tools
- Add a new data export feature
By considering reach, impact, confidence, and effort, the RICE prioritisation pattern can help the Data Platform Product Owner prioritise which work to tackle first, ensuring that the teams efforts are focussed on work that will have the greatest impact with the available resources.
Weighted Scoring
The Weighted Scoring prioritisation pattern is a method for prioritising work based on multiple factors or criteria. This pattern involves assigning a weight to each factor and then scoring each piece of work based on its performance for each factor. The scores are then multiplied by the weights and summed to determine the overall prioritisation score for each piece of work.