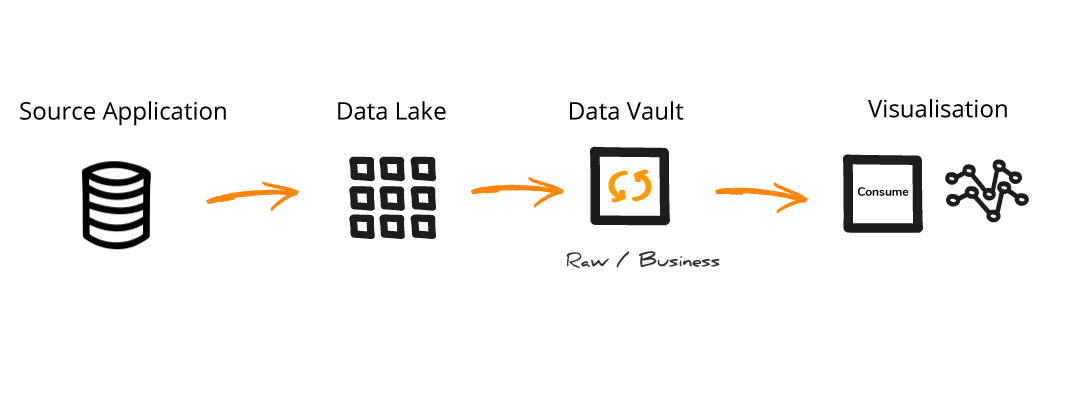
Problem
What problem is the pattern looking to solve
How do we store data centrally, in a way that provides context and absorbs changes, while also making it quickly available for use with minmal upfront work.
Solution
A generalised design which can be applied to solve the problem given the context

Context
A disucssion on when this pattern could be applied
TBD
The Data Lake pattern is similar to the Persistant Staging pattern and is often used interchangeably.
Impact
The likely consequences of adopting this pattern
FOR
Requires less modeling up front
Once you have identified the Change Data driver/key for each table the data can be quickly loaded into the Data Lake. This results int he data become available for use qucker, rather than having to wait until the Data Vault models are defined and implemented.
Only model data when it provides value
You can incrementally model and load the Data Vault Hubs, Sats and Links as and when it is required to provide data with context.
AGAINST
Increased data duplication
Some data is stored in both the Data Lake and Data Vault layers, increasing data duplication compared to other patterns.
Increased data complexity
While data is made available in the Data Lake quicker than some other Data Architecure patterns, the structure of this data matches the structure of the source system and will typically be more complex to use compared to data that has been modeled with context already applied.
Increased data latency
The Data Lake introduces a new data layer compared to some of the other Data Architecture patterns. This introduces an addiotnal level of latency when moving data from source applications through to the consumable layers.
Related Patterns
Other patterns that are similair to this pattern or reliant upon it
Ask us to complete this pattern
Get in touch and let us know you would like us to complete this pattern next